Wenn psychische Erkrankungen früh erkannt und dadurch auch rechtzeitig behandelt werden, leiden die Betroffenen weniger und werden mit größerer Wahrscheinlichkeit wieder gesund. Bisher erfordert es menschliche Expertise, Anzeichen für psychische Erkrankungen im Alltag zu erkennen. Doch inzwischen gibt es immer mehr Ansätze, psychische Erkrankungen automatisch basierend auf Informationen aus sozialen Netzwerken zu erkennen. Die Frage ist: Funktioniert das wirklich und welche Risiken können damit einhergehen?
Maria ist eine erfolgreiche Influencerin, die mit ihren Videos jeden Tag tausende Abonnent*innen erreicht. Während sie sich in sozialen Netzwerken stets von ihrer fröhlichen Seite präsentiert, fühlt sie sich in letzter Zeit immer häufiger leer und antriebslos. Als sie die Nachrichten ihrer Abonnent*innen lesen will, sieht sie eine Benachrichtigung durch das soziale Netzwerk: Eine Analyse-Software habe bei ihr in den letzten Wochen Auffälligkeiten erkannt, die auf eine Depression hinweisen. Maria ist fassungslos: Woher will die Software ihre psychische Gesundheit kennen? Sollte sie diese Nachricht ernst nehmen?
Ob Dystopie der Überwachung oder Utopie der schnellen Erkennung von psychischen Erkrankungen – diese fiktive Geschichte klingt für die meisten vermutlich sehr futuristisch. Dabei forschen bereits zahlreiche Wissenschaftler*innen zur Erkennung von psychischen Erkrankungen in sozialen Netzwerken. Bei fast einer Milliarde Personen mit psychischen Erkrankungen weltweit (World Health Organization, 2023) haben die hierbei entwickelten Systeme enormes Potenzial, psychisches Leid zu erkennen und somit den Weg für eine frühzeitige Behandlung zu ebnen. Gleichzeitig müssen persönliche und gesundheitliche Informationen besonders geschützt werden und der Einsatz von Algorithmen darf nicht zu Diskriminierung führen. Dieser Artikel gibt einen Überblick darüber, wie psychische Erkrankungen mithilfe von künstlicher Intelligenz in sozialen Medien erkannt werden können, wie gut das bereits funktioniert und welche ethischen Probleme damit einhergehen können.
Wie lernen Maschinen?
Um später nachvollziehen zu können, wie verschiedene Systeme zur Erkennung von psychischen Störungen vorgehen, hilft es zunächst zu verstehen, wie Maschinen „lernen“. Hierbei kann unterschieden werden zwischen regelbasierten Systemen und Verfahren, die auf künstlicher Intelligenz basieren.
Regelbasierte Systeme
Regelbasierte Systeme stellen einen traditionellen Ansatz der automatischen Datenverarbeitung dar. Die Entwickler*innen legen bei der Programmierung des Systems konkrete Regeln fest. Beispielsweise könnten Listen mit Wörtern erstellt werden, die auf eine Depression hinweisen: „Leere”, „antriebslos”, „Dunkelheit”... Dann werden Regeln festgelegt, welche Wortkombinationen vorliegen müssen, damit eine Depression vermutet wird. Obwohl regelbasierte Ansätze immer noch in vielen Bereichen eingesetzt werden, liefert künstliche Intelligenz oft deutlich bessere Ergebnisse. Hierbei führen Maschinen Aufgaben aus, die üblicherweise mit intelligenten Lebewesen, insbesondere dem Menschen, in Verbindung gebracht werden. Im Folgenden gehen wir näher auf Machine Learning, eine Form von künstlicher Intelligenz, ein.
Machine Learning
Beim Machine Learning (maschinellen Lernen) beobachtet das System eine Menge an Daten und stellt selbst die Entscheidungsregeln auf. Je mehr Daten vorhanden sind, umso besser kann das System Muster erkennen, die das richtige Ergebnis liefern. Die Daten werden in zwei Phasen verarbeitet: In der Trainingsphase erhält das System Datenbeispiele, die nach Merkmalen sortiert sind, z. B. A) Depression liegt vor, B) keine Depression. Mithilfe von statistischen Verfahren werden Muster gesucht, die typisch für die bestimmte psychische Erkrankung sind und die eine korrekte Zuordnung ermöglichen (Zhang et al., 2022). In der Testphase werden dem System neue Datenbeispiele gezeigt und es wird untersucht, wie häufig es auf das richtige Ergebnis kommt. Die Maschine stellt also die Regeln auf, die entscheiden, mit welcher Wahrscheinlichkeit man ein bestimmtes Ergebnis vermuten kann. Menschen bestimmen aber, wie das System nach diesen Regeln sucht. Dabei probieren die Entwickler*innen unterschiedliche Verfahren aus und verwenden letztlich jene, die am zuverlässigsten funktioniert.
Deep Learning
Zur Erkennung von psychischen Erkrankungen wird eine bestimmte Form von Machine Learning zunehmend mehr verwendet: das Deep Learning (tiefes Lernen; Zhang et al., 2022). Hierbei sucht das System, wie beim regulären Machine Learning, in großen Datenmengen nach Mustern und stellt Regeln auf, nach denen dann neue Daten beurteilt werden können. Neu ist beim Deep Learning, dass die Verarbeitung durch sogenannte künstliche neuronale Netze erfolgt. Ein flaches neuronales Netz besteht aus drei Schichten. Eine erste Schicht Neuronen enthält die mathematischen Repräsentationen eines Trainingsbeispiels. Eine mittlere Schicht von Neuronen verarbeitet die Werte der ersten Schicht so, dass die Neuronen große Werte (Aktivierungen) beinhalten, falls das Beispiel ein wichtiges Muster (also relevante Informationen) beinhaltet. Eine letzte Schicht enthält so viele Neuronen, wie man Werte als Ergebnis erhalten möchte – z. B. drei Neuronen für keine Depression, milde Depression oder starke Depression. Das Ergebnis entspricht dem Neuron der letzten Schicht, das den höchsten Wert aufweist. Ein tiefes neuronales Netz hat mehrere mittlere Schichten. Die Bearbeitung erfolgt also in vielen Schritten, wodurch die Modelle leistungsstärker werden (Su et al., 2020).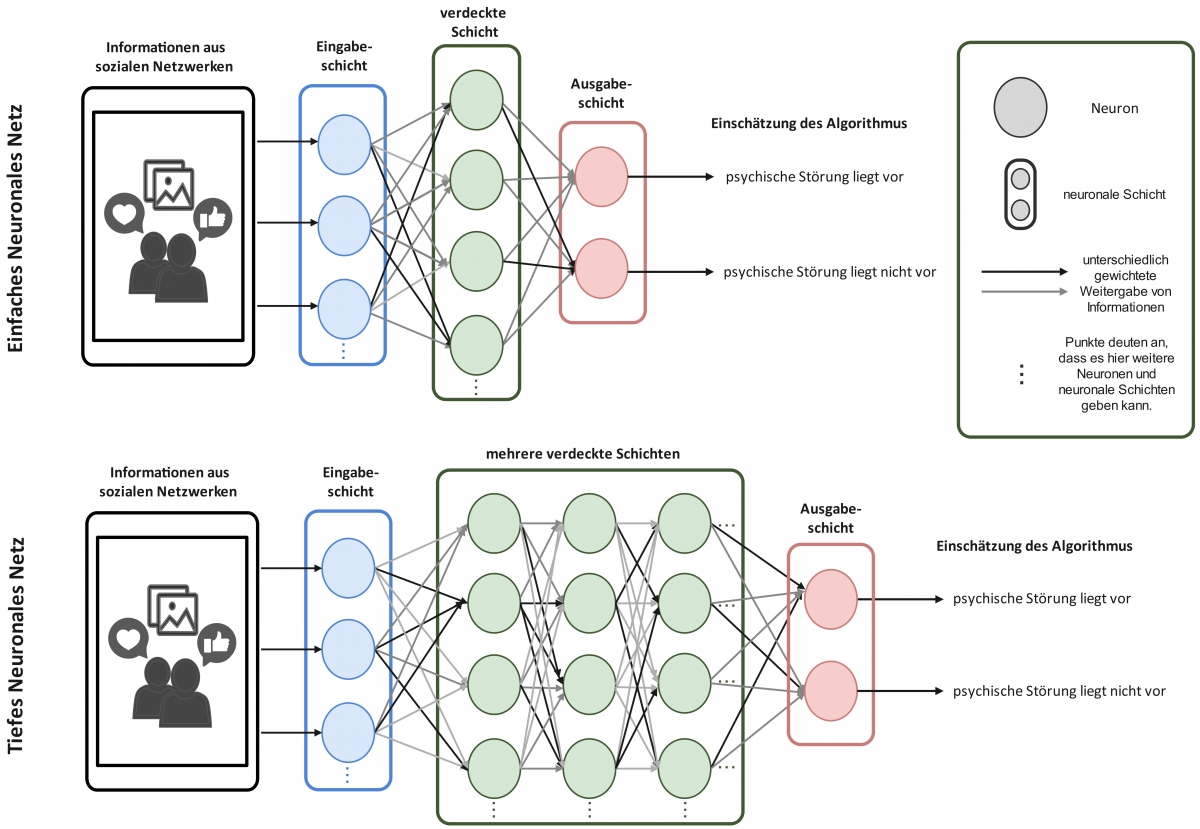
Wie gut können psychischen Erkrankungen in sozialen Netzwerken erkannt werden?
Wie gut das System psychische Symptome erkennt, hängt vom jeweiligen System, der psychischen Erkrankung sowie den vorhandenen Informationen über die Person ab. Im Folgenden werden Beispielsysteme für häufige psychische Erkrankungen betrachtet.
Depressionen
Depression ist eine psychische Erkrankung, bei der Betroffene über mindestens zwei Wochen hinweg anhaltend niedergeschlagen sind, sich erschöpft fühlen oder das Interesse an alltäglichen Aktivitäten verlieren. Es können auch Symptome wie Reizbarkeit oder innere Leere auftreten (World Health Organization, 2019). Depressionen stellen weltweit die häufigste psychische Erkrankung im Erwachsenenalter dar (World Health Organization, 2023).
Um einzuschätzen, ob Reddit-Nutzer*innen eine Depression aufweisen, wurde ein Deep-Learning-System namens EnsemBERT entwickelt (Ravenda et al., 2025). Reddit ist ein soziales Netzwerk, auf dem sich Nutzer*innen öffentlich zu verschiedenen Themen austauschen können. Für die Entwicklung des Systems wurden öffentliche Reddit-Beiträge von 100 Nutzer*innen analysiert. Diese hatten entweder in ihren Beiträgen explizit von einer Depression berichtet oder schrieben in Foren, die sich mit psychischer Gesundheit befassen. Das System suchte gezielt nach Reddit-Beiträgen, die inhaltlich übereinstimmen mit Aussagen, die auch im BDI-II (Beck et al., 1996) abgefragt werden, einem etablierten diagnostischen Fragebogen, mit dem das Ausmaß depressiver Symptome eingeschätzt wird. Beim BDI-II geben Patient*innen keine reinen Ja- oder Nein-Antworten, sondern geben an, wie sehr sie bestimmten Aussagen zustimmen, zum Beispiel: „Ich bin traurig“ oder „Ich habe Schwierigkeiten, mich zu konzentrieren.“ Auf Basis der Nutzer*innen-Beiträge in Reddit sagte das System vorher, wie die Personen im BDI-II antworten würden. Beim Testen erreichte EnsemBERT eine höhere Genauigkeit als viele bisherige Modelle, wobei die Vorhersagen für die einzelnen Aussagen im Schnitt weniger als einen Punkt (von vier Abstufungen) abwichen. Die Depressionseinstufung des Fragebogens in minimal, mild, moderat oder schwer wurde vom System in 7 von 10 Fällen korrekt eingeschätzt (Ravenda et al., 2025). Besonders innovativ war, dass das System nicht nur das Vorliegen einer Depression, sondern auch einzelne Symptome wie Schlafprobleme oder Hoffnungslosigkeit diagnostizieren konnte. Jedoch stehen Replikationen noch aus, welche aufgrund einer kleinen Datenmenge wichtig wären. Zudem ist die Einschätzung des Modells für eine Anwendung in der Praxis bisher nicht ausreichend zuverlässig.

Essstörungen
Anorexia nervosa (Magersucht) ist die häufigste psychisch bedingte Essstörung. Für eine Anorexie charakteristisch sind starker Gewichtsverlust und Untergewicht. Die Betroffenen haben außerdem häufig eine verzerrte Wahrnehmung ihres eigenen Körpers (World Health Organization, 2021).
Twitter (mittlerweile in X umbenannt) ist ein soziales Netzwerk, auf dem Nutzer*innen öffentlich kurze Textnachrichten posten. Um zwischen Nutzer*innen mit und ohne Essstörungen zu unterscheiden, wurde ein Machine-Learning-System namens ED-Filter entwickelt und auf den Daten von 37.405 Posts trainiert. Das System filtert die Posts zunächst nach bestimmten Wörtern, Satzmustern oder Themenkombinationen, die Informationen über die psychische Gesundheit der Person beinhalten könnten. So filtert das System Aussagen wie: „Ich hasse meinen Körper.“ Die gefilterten Informationen werden anschließend analysiert, um eine Vorhersage zu treffen, ob eine Essstörung vorliegt oder nicht. Das System konnte in etwa acht von zehn Fällen korrekt einschätzen, ob essgestörtes Verhalten vorliegt. Nutzer*innen mit einer selbst berichteten Essstörung unterschieden sich von anderen vor allem darin, dass sie stärker emotionale, körperbezogene und kontrollorientierte Sprache verwendeten (Naseriparsa et al., 2025). Es kann positiv hervorgehoben werden, dass ED-Filter gezielt interpretierbare Merkmale auswählen und damit nachvollziehbar bleibt, worauf das System seine Einschätzung stützt. Kritisch zu sehen ist jedoch die Auswahl der Daten: Es wurden nur Personen berücksichtigt, die öffentlich über ihre Diagnose schrieben, und die Diagnose wurde nur selbst berichtet.
Basierend auf Daten von sozialen Netzwerken kann künstliche Intelligenz also eine Einschätzung über die psychische Gesundheit von Nutzer*innen geben. Die Systeme wurden dabei in der Regel für eine oder wenige psychische Erkrankungen und ein soziales Netzwerk entwickelt (Zhang et al., 2022). Trotz des großen Potentials wird die automatische Erkennung von psychischen Erkrankungen aber auch kontrovers diskutiert und es müssen noch einige Schwierigkeiten bewältigt werden (Zhang et al., 2022), die wir im nächsten Abschnitt betrachten.
Welche Herausforderungen gibt es bei der automatischen Erkennung von psychischen Erkrankungen?
Daten und Ethik
Für Machine Learning und Deep Learning sind große Datenmengen notwendig. Die Systeme identifizieren Muster, in denen sich Personen mit und ohne eine bestimmte psychische Erkrankung unterscheiden. Erst bei der Auswertung von sehr vielen Daten kann erkannt werden, welche Merkmale typisch für die psychische Erkrankung sind (Chancellor & Choudhury, 2020; Zhang et al., 2022). Gleichzeitig handelt es sich um ein sehr sensibles Thema, bei dem persönliche Daten besonders geschützt werden sollten, weshalb verbindliche ethische Standards für die Verwendung von Daten in der Forschung und im Gesundheitssektor wichtig sind (Golder et al., 2017; Iyortsuun et al., 2023). In der Europäischen Union (EU) verpflichtet der Digital Services Act (DSA) seit 2024 sehr große Online-Plattformen mit mehr als 45 Millionen monatlich aktive Nutzer*innen dazu, bestimmten geprüften Forschenden Zugang zu ausgewählten Daten, wie öffentlichen Nutzer*innen-Profilen, zu gewähren. Voraussetzung ist ein Antrag, aus dem hervorgeht, dass das Forschungsvorhaben im öffentlichen Interesse liegt und keine kommerziellen Ziele verfolgt. Daten aus privaten Accounts oder Inhalten, die nicht öffentlich einsehbar sind, dürfen nur in ganz bestimmten Sonderfällen verarbeitet werden – etwa, wenn eine ausdrückliche Einwilligung der Nutzer*innen vorliegt (Verordnung (EU) 2022/2065, 2022, Art. 40; Verordnung (EU) 2016/679, 2016, Art. 9, 89).
Genauigkeit und Stabilität
Die Nutzung von maschinellen Systemen, z. B. für Rückmeldungen an Nutzer*innen, ist nur dann gerechtfertigt, wenn die Systeme zuverlässig sind. Zuverlässigkeit kann dabei in zwei Aspekte unterteilt werden. Erstens: Wie genau ist die Vorhersage? Das heißt: Wird bei Personen mit einer psychischen Erkrankung diese tatsächlich erkannt? Werden Personen ohne eine psychische Erkrankung korrekterweise als gesund eingestuft? Zweitens: Wie stabil ist die Vorhersage? Das bedeutet: Bleibt die Vorhersage bei sehr unterschiedlichen Daten genau? In den vergangenen Jahren sind Systeme zur Erkennung von psychischen Erkrankungen, die Informationen aus sozialen Netzwerken verwenden, leistungsstärker geworden. Die meisten Systeme funktionieren allerdings nur dann gut, wenn sie Nachrichten und Personen einstufen sollen, die den Daten ähneln, mit denen sie gelernt haben (Zhang et al., 2022). Darüber hinaus hängt die Vorhersagegenauigkeit der Systeme von Alter, Gender und Ethnie der Nutzer*innen ab. So wurde bei Frauen beispielsweise häufiger fälschlicherweise eine Essstörung vorhergesagt als bei Männern (Solans Noguero et al., 2023), während Depressionen bei schwarzen Amerikaner*innen schlechter erkannt wurden als bei weißen Amerikaner*innen (Rai et al., 2024).
Interpretierbarkeit und Akzeptanz
Um gesellschaftliche Akzeptanz für die maschinelle Erkennung von psychischen Erkrankungen in sozialen Medien zu erreichen, müssen die Entscheidungen interpretierbar sein – Menschen sollten also nachvollziehen können, wie das System eine bestimmte Entscheidung getroffen hat. Nur wenn sichergestellt werden kann, dass die Systeme auf tatsächlich relevante Merkmale achten, sollten sie in der Praxis verwendet werden (Miller, 2019; Zhang et al., 2022). Bis jetzt ist bei den meisten Systemen allerdings noch unklar, wie sie zu ihrer Einschätzung der psychischen Gesundheit einer Person kommen (Su et al., 2020). Das liegt daran, dass es sich bei den Mustern und Regeln, die die Systeme finden, um mathematische Objekte wie Matrizen handelt. Diese beschreiben hochdimensionale und komplexe Interaktionen von Merkmalen und sind für Menschen in der Regel nicht nachvollziehbar. Zahlreiche Wissenschaftler*innen erforschen, wie die Entscheidungsprozesse existierender Modelle besser verstanden und neue Modelle transparenter konstruiert werden können.

Interdisziplinarität
Forschung zur automatischen Erkennung von psychischen Erkrankungen findet an der Schnittstelle verschiedener Wissenschaftsdisziplinen statt. Daran beteiligt sind etwa die Informatik mit der maschinellen Verarbeitung von menschlicher Sprache und die Psychologie, die menschliches Erleben und Verhalten untersucht. Wenn Expert*innen aus nur einem dieser Bereiche die Schnittstelle der beiden Disziplinen erforschen, kann dies zu methodischen Mängeln führen. Informatiker*innen achten gegebenenfalls nicht hinreichend auf psychologisch-fundierte Definitionen der psychischen Erkrankungen und ihrer Symptome. Psycholog*innen kennen sich nicht unbedingt mit Machine Learning aus, wodurch es zu Verzerrungen der Ergebnisse kommen kann (Chancellor & Choudhury, 2020). Wir benötigen daher Forschungsteams, in denen Expert*innen verschiedener Bereiche zusammenarbeiten. So kann darauf geachtet werden, dass Standards einer psychologischen Diagnose eingehalten werden, bei Personen in der Vergleichsgruppe keine psychische Erkrankung vorliegt und die Systeme eine zuverlässige und faire Vorhersage treffen.
Werden Psycholog*innen bald durch Maschinen ersetzt?
Die Diagnose von psychischen Erkrankungen erfolgt nach festgelegten Qualitätsstandards. Psychotherapeut*innen verwenden hierfür standardisierte Fragebögen und führen klinische Interviews durch, wobei sie auch individuelle Aspekte wie Lebensgeschichte und Körpersprache beachten. Obwohl künstliche Intelligenz diese Standards noch nicht zufriedenstellend erfüllen kann, könnte sie helfen, in sozialen Netzwerken Anzeichen für psychische Erkrankungen zu erkennen (Zhao et al., 2022). Psychotherapeut*innen könnten daraufhin untersuchen, ob tatsächlich eine psychische Erkrankung vorliegt. Dadurch wäre es möglich, frühzeitig einzugreifen und Personen in ihrer Genesung zu unterstützen (Iyortsuun et al., 2023). Es ist jedoch zu beachten, dass nicht alle soziale Medien nutzen und es große Unterschiede gibt, wie viel Person online über sich preisgeben (Zhao et al., 2022). Darüber hinaus ist unklar, inwiefern Algorithmen die Zuverlässigkeit von Informationen einschätzen können. Künstliche Intelligenz könnte also Therapeut*innen bei der Diagnose von psychischen Erkrankungen unterstützen. Dass künstliche Intelligenz in diesem Bereich Therapeut*innen ersetzt, ist auf absehbare Zeit allerdings nicht zu erwarten.

Was können wir nun Maria aus der fiktiven Geschichte vom Anfang dieses Artikels raten? Maria sollte wissen, dass die Einschätzung der Analyse-Software nicht mit einer Diagnose durch eine*n Psychotherapeut*in gleichzusetzen ist. Anderseits wissen wir nun, dass künstliche Intelligenz bei gutem Training und zuverlässigen Daten zu einer hilfreichen Einschätzung der psychischen Gesundheit kommen kann. Wir könnten Maria daher empfehlen, eine psychotherapeutische Praxis oder Ambulanz aufzusuchen. Dadurch kann sie eine eindeutige Diagnose erhalten, ob eine psychische Erkrankung vorliegt – und wenn notwendig, professionelle Hilfe in Anspruch nehmen.
Literaturverzeichnis
Beck, A. T., Steer, R. A., & Brown, G.K. (1996). Manual for the Beck Depression Inventory-II. Psychological Corporation.
Chancellor, S., & Choudhury, M. D. (2020). Methods in predictive techniques for mental health status on social media: a critical review. Npj Digital Medicine, 3(1). https://doi.org/10.1038/s41746-020-0233-7
Golder, S., Ahmed, S., Norman, G., & Booth, A. (2017). Attitudes toward the ethics of research using social media: a systematic review. Journal of Medical Internet Research, 19(6), e195. https://doi.org/10.2196/jmir.7082
Iyortsuun, N. K., Kim, S.-H., Jhon, M., Yang, H.-J., & Pant, S. (2023). A review of machine learning and deep learning approaches on mental health diagnosis. Healthcare, 11(3), 285. https://doi.org/10.3390/healthcare11030285
Naseriparsa, M., Sukunesan, S., Cai, Z., Alfarraj, O., Tolba, A., Rabooki, S. F., & Xia, F. (2025). ED-Filter: dynamic feature filtering for eating disorder classification. Artificial Intelligence Review, 58, 237. https://doi.org/10.1007/s10462-025-11244-4
Miller, T. (2019). Explanation in artificial intelligence: insights from the social sciences. Artificial Intelligence, 267, 1–38. https://doi.org/10.1016/j.artint.2018.07.007
Rai, S., Stade, E. C., Giorgi, S., Francisco, A., Ungar, L. H., Curtis, B.,& Guntuku, S. C. (2024). Key language markers of depression on social media depend on race. Proceedings of the National Academy of Sciences, 121(14), e2319837121. https://doi.org/10.1073/pnas.2319837121
Ravenda, F., Preti, A., Poletti, M., Mira, A., Crestani, F., & Raballo, A. (2025) Transforming social media text into predictive tools for depression through AI: A test-case study on the Beck Depression Inventory-II. PLOS Digital Health, 4(6), e0000848. https://doi.org/10.1371/journal.pdig.0000848
Solans Noguero, D., Ramírez-Cifuentes, D., Ríssola, E. A., & Freire, A. (2023). Gender bias when using artificial intelligence to assess anorexia nervosa on social media: data-driven study. Journal of Medical Internet Research, 25. https://doi.org/10.2196/45184
Su, C., Xu, Z., Pathak, J., & Wang, F. (2020). Deep learning in mental health outcome research: a scoping review. Translational Psychiatry, 10(1). https://doi.org/10.1038/s41398-020-0780-3
Verordnung - 2022/2065 - EN - EUR-LEX. (o. D.). eur-lex.europa.eu
Verordnung - 2016/679 - EN - Datenschutz Grundverordnung - EUR-LeX. (o. D.). eur-lex.europa.eu
World Mental Health Report. (2022, 17. Juni). www.who.int
World Health Organization (2019). International classification of diseases for mortality and morbidity statistics (11th ed.). https://icd.who.int/
World Health Organization. (2021). International statistical classification of diseases and related health problems (11th ed.). https://icd.who.int/en
Zhang, T., Schoene, A. M., Ji, S., & Ananiadou, S. (2022). Natural language processing applied to mental illness detection: a narrative review. Npj Digital Medicine, 5(1). https://doi.org/10.1038/s41746-022-00589-7
Zhao, Y., He, X., Feng, Z., Bost, S., Prosperi, M., Wu, Y., Guo, Y., & Bian, J. (2022). Biases in using social media data for public health surveillance: A scoping review. International Journal of Medical Informatics, 164. https://doi.org/10.1016/j.ijmedinf.2022.104804
Bildquellen
Bild 2: Andrea Piacquadio via pexels
Bild 3: Anna Shvets via pexels
Bild 4: Oladimeji Ajegbile via pexels
- Log in to post comments
